Knight-Mozilla Learning Lab: Week 3
August 1st, 2011
Our lecturers in the Mozilla News Lab this week were Shazna Nessa, Director of Interactive at Associated Press, Mohamed Nanabhay, Head of Online at Al Jazeera English and Oliver Reichenstein of Information Architects.
Mohamed’s insights into adoption of new technology in the newsroom and the ways the web has affected not only consumption but production of news media gave me much food for thought. The News Tree was initially conceived as a tool for consumers (normal people) to quickly get up to speed on an evolving story, but I thought that it would also be useful to journalists charged with writing or researching a certain story, where the Tree would act as a jumping-off point for locating fruitful sources, gauging public opinion and determining further avenues of research.
I recently got in touch with a relative, known for his writing in the Scotsman, to seek feedback on my project. He thought it was “a cool idea” but describes himself as a member of “the dinosaur school of journalism” who believe good-old-fashioned talking to people is much more productive than using search engines and other digital tools to generate stories. Similarly, Mohammed recounted Al Jazeera’s scrapped plans for a citizen media portal and declared that he too prefers to conduct his own research rather than rely on submissions or automated source aggregation tools, which often simply return too much data to be of use.

It’s not surprising journalists prefer to conduct their own research rather than rely on content encountered on the web, particularly if they did not discover it themselves
In week one I wondered if the real power of my tool would lie “not in the wild tangle [of information] but in the pruned or grafted specimens its users will create and share”.
Rather than relying on data-scrapers and search algorithms to locate every source possible, the News Tree could grow (perhaps solely) from the submissions of teammates, the news room, or even the whole organisation. Staff would drop into the pot relevant sources or media they encountered or created, as a URL or file. The system would plot the item on the tree, showing any links to other items already present, author or submitter, chronological location etc.
The user locates a source they wish to share:

They add it to the tree by copy-and-pasting, or clicking-and-dragging:
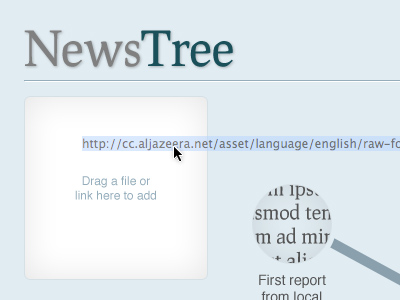
The Tree draws links with existing content based on metadata:

With HTML5 we can drag-and-drop files (ala DropMocks) and by simply using URLs and files we mostly sidestep two problems:
- Lack of technological expertise in newsroom staff; anyone who can copy and paste can contribute.
- Constantly changing APIs and feature sets of third-party tools, which may cripple or break aggregation software (mentioned by Mohamed).
This could also tackle Shazna’s problem where breaking news requires rapidly developed visualisations. The News Tree could stand in in the interim.
In theory all of the content would be peer-reviewed and trustworthy, having survived the scrutiny of the journalist. Editorial control remains intact and a collaborative, communal index of sources is born – which, by virtue of its visual nature, outshines any mere list of links.
Photograph credit: Robert Couse-Baker